Adobe
Introducing text recognition (OCR) to Acrobat mobile

Modernizing the PDF
Adobe Acrobat is well-known for popularizing PDFs as our digital counterparts to paper documents. With the popularity of mobile platforms, it is increasingly important to offer on-par capabilities with desktop applications right on your phone. An important part in modernizing Acrobat and PDFs is bringing Optical Text Recognition (OCR) to mobile platforms. With this feature, struggling to copy text and edit from an image is a problem of the past.
Company: Adobe Duration: 1.5 years Tools: Adobe XD, FigmaPlatform: iOS and Android mobile devices Role: Wireframing, iteration, prototyping
The Product
Adobe Acrobat offers multiple avenues of working on-the-go. Coming out in 2011 and 2012 respectively, you can download and use Acrobat on both iOS and Android platforms. During the past decade, the apps have ramped up competatively to offer the same great desktop features on mobile. The Acrobat mobile team at Adobe is directly responsible for the following products that I had the pleasure to work on:
My Role
During my time on this project, I was directly responsible for owning and developing this feature from start to end on both iOS and Android platforms. My responsibilities included:
- High/low fidelity UI work
- Prototyping
- Competitive Analysis Research
- Close collaboration with PMs and developers to ensure technical feasibility and correct implementation
- Post build QA walk throughs and inspection
- Project and timeline management

Problem | Research
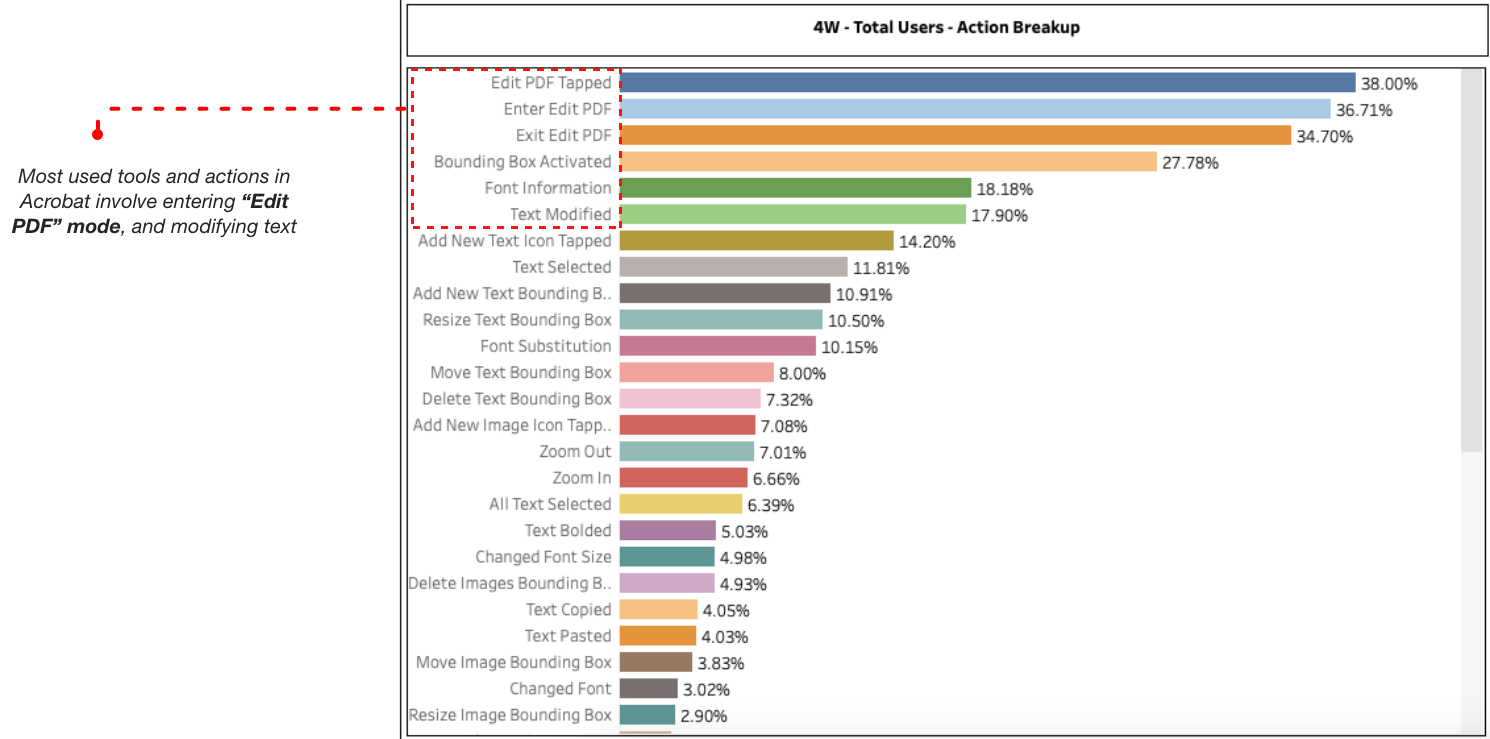
Scanned PDFs are essentially images, in PDF format. They have many limitations which do not allow the user to make changes to the document or even perform operations such as copy or highlight text. 17%-18% of all files opened in-app are scanned files which means a large chunk of our users are missing key functionalities that will enable them to successfully interact with their documents.
Working with PMs and developers
One of the most challenging aspects of this project was the complicated and restrictive technical limitations that popped up during the entire duration of the project. By utilizing my background (BA and MCS) in computer science I was able to successfully navigate the complicated technical nature of the project and work closely with developers to ensure that we strike a balance between what is possible, and what is ideal for the user resourcefully.
Research, understanding, and Explorations
blue lines, why we're doing it ppt, what it is like in the backend, apple vision explorations
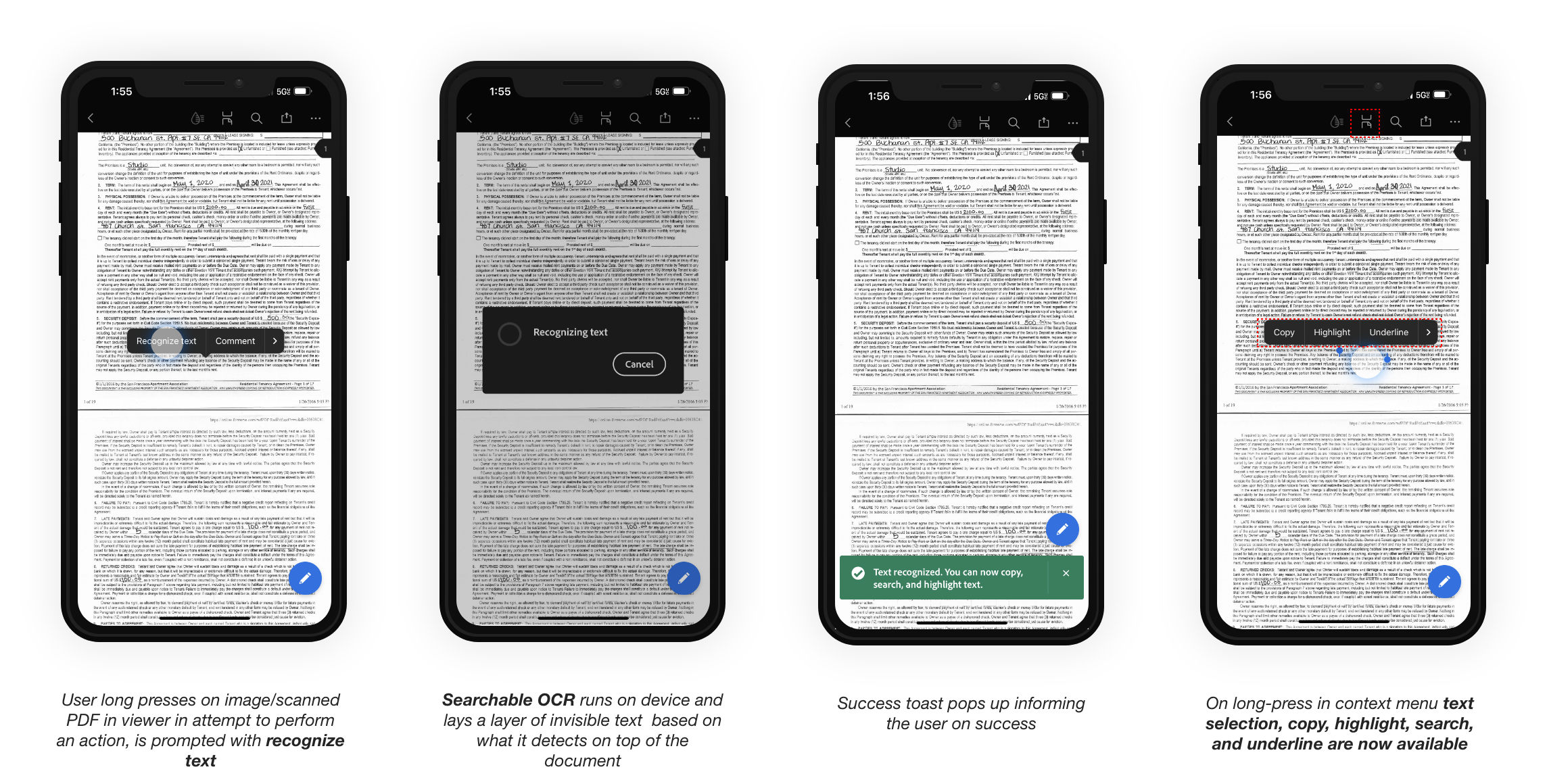
- Searchable OCR: Allows for quick processing by laying an invisible text layer over the original document. Users can now highlight, comment, and copy text.
- Editbale OCR: The document will be reconstructed, effectively allowing users to edit and modify text and images like any other PDF
- Scanned PDF: A PDF that is essentially an image and has no text data/strings that a PDF reader would be able to detect.
Dividing the project into phases | MVP and beyond
This large feature roll-out required design to understand and scope work to come up with an MVP which could scale to allow full features within the span of the project timeline. The phases were divided into the following:
Phase 1 (iOS rollout)
Features:- Copy
- Highlight
- Underline
- Search
Improvements:
- Faster processing (compared to editable OCR, coming up in the next phase)
- Original document left intact
Restrictions:
- Unable to automatically run OCR on document open due to technical restrictions
- No text editing
- Limited number of languages supported
Phase 2 (iOS rollout)
Features:- Text editing
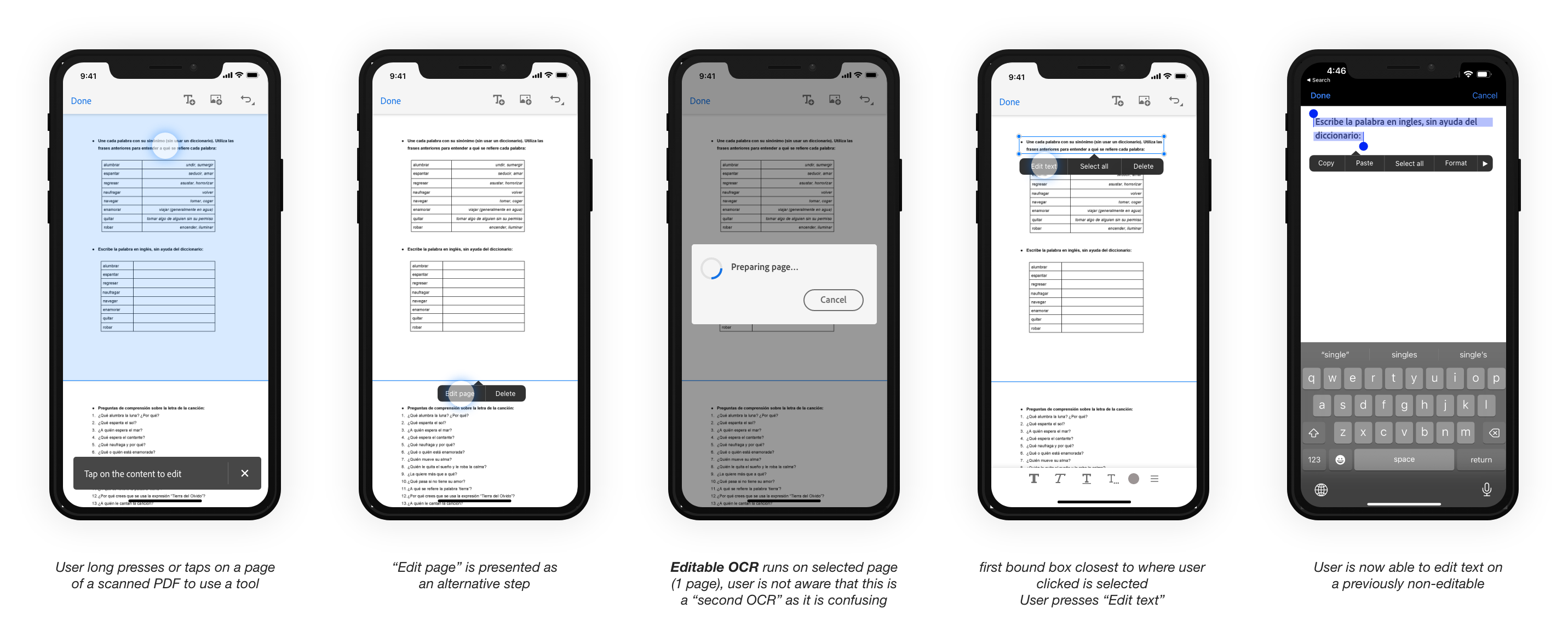
- Long processing time: the longer the document, the slower experience, worst case is 17 seconds for one page
- Reconstruction of original document == unpredictable irreversable results due to autosave on mobile
Phase 3 (iOS rollout)
Features:- Expanded supported languages
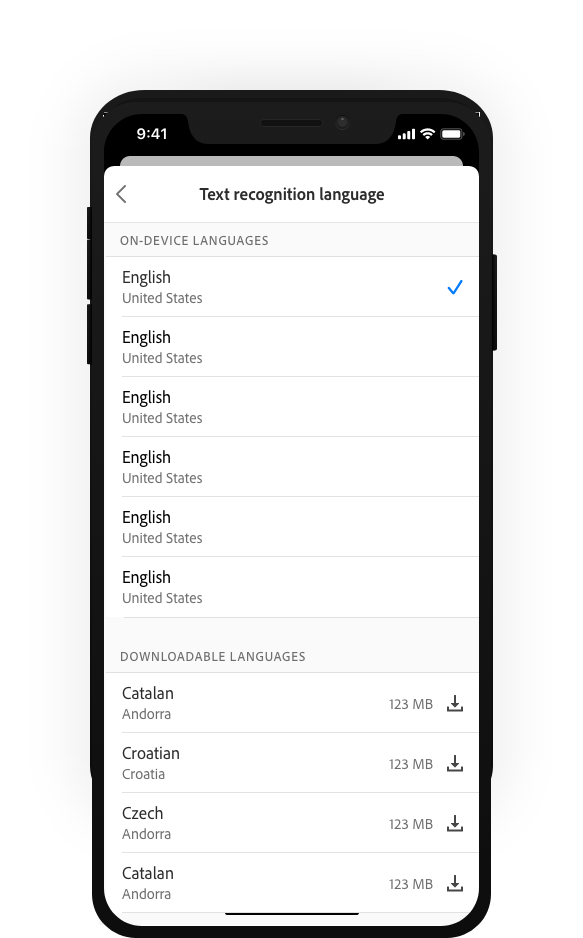
- Large datapacks for languages
- Manual downloads needed for certain langauges
For the remainder of the project, I went on to work on Android version with the Android engineering team which followed the same release pattern but had it's own designs and challenges.
Post release
As of December 2023, OCR was released to all users on all acrobat platforms (iOS, Android, iPad, tablet) and has been well recieved in the app store. In addition to good reception from the general public, the feature brought generated a total GNARR of over $400,000 from just subscriptions on Android and $235,000 on iOS respectively over a year.
The future and scalability
While designing this feature, I was extremely concerned with scalability and worked closely with developers to ensure that sometime in the future we can enable automatic language detection and run OCR automatically without blocking the user. The goal is for the user to not even notice the difference between a scanned image PDF and a regular text enabled PDF.
Takeaways
Gaining a deep understanding of the technology behind your designs is extremely important, having a background in computer science allows me to have deep technical discussions with developers and expedite and gain the trust of stakeholders much faster allowing me to create intentional and feasible designs that can be translated into code.